Rethinking assessment Part 1: How can we tell if students are making progress?
Nov 15, 2015
Is it progress if a cannibal uses a fork?
Stanislaw J. Lec
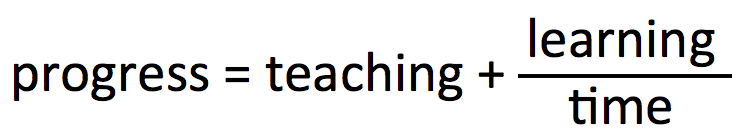
In What If Everything We Knew About Education Was Wrong? I argue that
Progress is just a metaphor. It doesn’t really describe objective reality; it provides a comforting fiction to conceal the absurdity of our lives. We can’t help using metaphors to describe learning because we have no idea what it actually looks like. Even though our metaphors are imprecise approximations, the metaphors we use matter. They permeate our thinking. (p. 148-9)Whenever we attempt to assess learning it's very hard to see past this metaphor of progress which results in some really dreadful hokum. Many many schools are assessing very poor proxies for learning and concluding that, hey presto! progress is being made. They might be able to pull over inspector's eyes but I strongly suspect external results will fail to marry up with internal judgements about progress in moare than a few cases. Whenever we assess students' work we should always ask two questions:
- What is it we actually want to measure?
- How can we go about measuring it with reasonable levels of reliability and validity?
Examination boards have responded to the inherent weakness of markschemes by dreaming up ways to increase the reliability of their rubrics but all this comes at the cost of validity. Lots of people seem to feel that GCSEs or A levels don't tell us what we actually want to know. The question is, what do we want to know? In most case the answer is as simple, and as complex, as how good a student is at a particular subject.
Consider, for example, English. Most people will agree that we want to find out how good students are at comprehension (reading) and composition (writing). But what does that actually mean? What is we really want students to be able to do?Most of what we assess are proxies. We design rubrics to be able to tell us everything about a piece of work but they end up telling us nothing useful. Exam rubrics would have us believe that we can assess the quality of a student's work across a range of AOs but in reality it's only really possible to assess one thing at a time. An exam should, if it is to tell us anything useful, be designed like a scientific experiment with as many of the variables controlled as possible.
Here are the criteria against which writing is assessed in the new English Language GCSE:
AO5
- Communicate clearly, effectively and imaginatively, selecting and adapting tone, style and register for different forms, purposes and audiences.
- Organise information and ideas, using structural and grammatical features to support coherence and cohesion of texts.
- Candidates must use a range of vocabulary and sentence structures for clarity, purpose and effect, with accurate spelling and punctuation.
What on earth can we do when the most reliable estimations of progress we have are so, well, unreliable? Finally, I have something other than a council of despair to offer. On Friday I spent the morning with Dr Chris Wheadon of nomoremarking. He has been using comparative judgement to increase the reliability of human judges to assess quality. Unlike making judgements of quality in isolation, we're really good at making comparisons.
Here's an example. How good, on a scale of 1 - 24 is this?

Hard isn't it? Try using the AOs above. Does that help? What about if I give you a rubric:
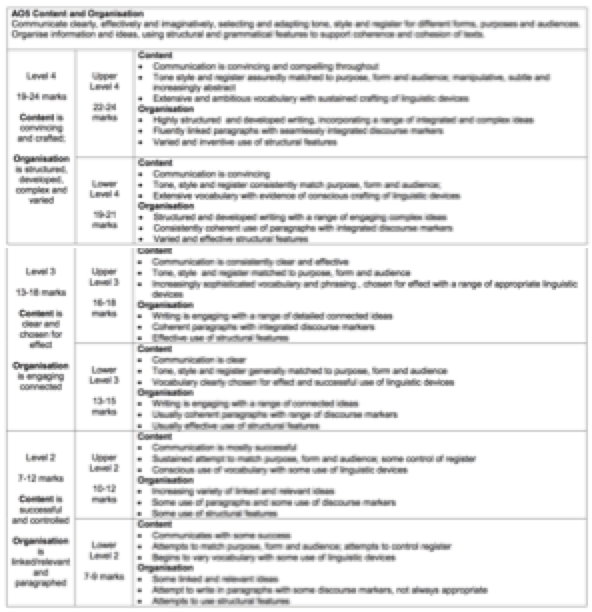
Does that help? Even if you did manage to award a mark which a majority of other people agreed with, how long would it take you?
Now try this:
Which is better?

Easy, isn't it. Judging requires a different mindset to marking and, ideally. you'll make your judgement in about 30 seconds. Now imagine that the judgements were made by a number of different experts and those judgements were aggregated. How reliable do you think the judgement would be? The formula Dr Wheadon recommends is "multiplying the number of scripts you have by 5. So if you have 10 scripts we would advise 50 judgements. Under this model each script is judged 10 times."
So what does all this have to do with assessing progress? What Chris and his team have been trialling in a number of schools is running a comparative judgement at the beginning or Year 7 and the running another, on a similar question, at the end of Year 7. In most schools, children are clearly making progress: their answers are, according to the aggregated judgement of a number of experts, better in the second test than the first. In some schools results soar with children achieving vastly superior scores in the space of a year. Alarmingly, in other schools, results tank. All this should, of course, be treated with caution, but surely this is valuable information which every teacher and every school would want to know?Perhaps predictably, the schools in which results have dropped have quietly withdrawn form the trial, but how else can we ever reliably know if teaching is having a positive effect?
It seems to me that this kind of comparative judgement provides rich information about students' apparent progress which, as long as the data wasn't used punitively, could be hugely useful in informing teachers' professional development and for schools to have a clear sense of what was happening within years. I suggested to Chris that "no more marking" failed to convey the power of his system. Maybe it would appeal more to schools if marketed as proof of progress"?
In Part 2, I will explore some of the barriers to rethinking assessment.
The Learning Spy Substack is a sharp, provocative dispatch from the front lines of education, where ideas are tested, myths are challenged, and nothing is taken for granted.
Join me on Substack